
0. はじめにのはじめに
2019年6月にGoogle自身がこの方法はdeprecated(廃止予定)であるとしました。2020年3月31日にRaspberry Pi 4 で動作を確認しましたが、いずれ動作しなくなる可能性はありますのでそのつもりでご覧ください。1. はじめに
本サイトでは以前、「Raspberry Pi + Julius + LIRC により家電製品を音声認識で操作する」という記事を紹介しました。これは、Juliusという音声認識エンジンをRaspberry Piにインストールして音声認識を実現し、その結果に基づいて家電を操作するものでした。
それに対し、本ページでは音声認識をRaspberry Piにインストールしたソフトウェアではなく、クラウド上のサービスで行う例を紹介します。
この方法は、Raspberry Piが常にインターネットに接続していなければならないという欠点があるものの、音声認識の精度が高いというメリットがあります。両方試してみて比較するのも良いでしょう。
下図は、それを実現している様子を示したものです。

また、動作中の動画が下記になります。
2. 本ページの内容を実現するために必要なもの
本ページで解説する内容はクラウドサーバーとの連携が必要なため、書籍やサイトで解説してきた内容の中で最も難易度が高くなっております。ご注意ください。また、実行には下記のものが必要です。
- Googleのアカウント(GmailやAndroidスマートフォンで利用するもの)
- Raspberry Piを常時インターネットに接続する環境
- マイク(後述)
- スピーカー(後述)
3. 音声入力(マイク)と音声出力(スピーカー)の設定
本ページの内容を実現するためには、マイクとスピーカーが必要です。どのような機器を用意すればよいか解説します。まず、マイクからです。Raspberry Piにはマイクの接続端子がありませんので、利用できる機器をあらかじめ調べておく必要があります。
本ページでは、マイクを接続するためのデバイスとして「USBマイク系」と「USBサウンドデバイス系」の2系統を試しました。
「USBマイク系」としては下記の2種類を試しました。
「USBサウンドデバイス系」としては下記の3種類を試しました。
- Creative Sound Blaster Play!3 SB-PLAY3
- Creative Sound Blaster Play!2 SB-PLAY2
- Creative Sound Blaster Play! SB-PLAY
のようなものがあります。
以上の「USBマイク系」と「USBサウンドデバイス系」のどれかからお好みの方法を選んでください。なお、上に示した動画では「SANWA SUPPLY MM-MCU02BK USBマイクロホン」を用いています。
一方、スピーカーについては、ミニプラグで接続可能なものであれば何でも構いません。ただし、ミニプラグでのスピーカーの接続先については3通りの選択肢があります(後述します)。
以上の物品を用意し接続した後、それらを利用可能にする設定を行います。これは、「用いるOSのバージョン」および「用いるマイクとスピーカーの組み合わせ」により計6パターンの選択肢がありますので、下記のうち該当する内容を実行してください。
3.1 (2020年2月までのOS) USBマイク+Raspberry Pi本体のミニプラグ端子へのスピーカー接続
ターミナルで以下の3コマンドを順番に実行してください。$ amixer cset numid=3 1 $ wget https://raw.githubusercontent.com/neuralassembly/raspi/master/asoundrc $ mv asoundrc .asoundrc
3.2 (2020年2月までのOS) USBマイク+HDMIディスプレイへのスピーカー接続
ターミナルで以下の3コマンドを順番に実行してください。$ amixer cset numid=3 2 $ wget https://raw.githubusercontent.com/neuralassembly/raspi/master/asoundrc $ mv asoundrc .asoundrc
3.3 (2020年2月までのOS) USBサウンドデバイスへのマイクとスピーカーの接続
ターミナルで以下の2コマンドを順番に実行してください。$ wget https://raw.githubusercontent.com/neuralassembly/raspi/master/asoundrc2 $ mv asoundrc2 .asoundrc
3.4 (2020年5月以降のOS) USBマイク+Raspberry Pi本体のミニプラグ端子へのスピーカー接続
ターミナルで以下の2コマンドを順番に実行してください。$ wget https://raw.githubusercontent.com/neuralassembly/raspi/master/asoundrc3 $ mv asoundrc3 .asoundrc
3.5 (2020年5月以降のOS) USBマイク+HDMIディスプレイへのスピーカー接続
ターミナルで以下の2コマンドを順番に実行してください。$ wget https://raw.githubusercontent.com/neuralassembly/raspi/master/asoundrc4 $ mv asoundrc4 .asoundrc
3.5 (2020年5月以降のOS) USBサウンドデバイスへのマイクとスピーカーの接続
ターミナルで以下の2コマンドを順番に実行してください。$ wget https://raw.githubusercontent.com/neuralassembly/raspi/master/asoundrc5 $ mv asoundrc5 .asoundrc
3.4 マイクとスピーカーの動作チェック
さて、3.1~3.3のどれかの方法でマイクとスピーカーの接続および設定が終わったら、動作チェックしてみましょう。まずはスピーカーのチェックです。ターミナルを起動して下記のコマンドを実行してみましょう。既に述べたように、本ページのコマンドはコピーと貼り付けによる実行を推奨します。
$ speaker-test -t wav「Front, Left, …」という音声がスピーカーから流れるはずです。止めるにはターミナル上でキーボードのCtrlキーを押しながらcキーを押します(Ctrl-cといいます)。
次に、マイクの動作チェックを行いましょう。下記のコマンドを実行すると、5秒間の音声がour.rawというファイル名で保存されますので、マイクに向かって話しかけてみましょう。
$ arecord --format=S16_LE --duration=5 --rate=16000 --file-type=raw out.raw録音が終わったら、下記のコマンドで再生してみます。
$ aplay --format=S16_LE --rate=16000 out.rawマイクに話しかけた音声が再生されたら動作チェックは成功です。
なお、機器のボリュームの調節は下記のコマンドで起動するアプリケーションを用いるのですが、操作方法にかなり癖があります。
$ alsamixeralsamixerの終了コマンドとして[ESC]キーは覚えておきましょう。まず、[F6]キーでサウンドカードを選択します。USBマイクの場合、矢印の上下キーで「1 USB PnP Audio Device」を選択してEnterを押します。2020年5月以降のOSならば「2 USB PnP Audio Device」となっているでしょう。 その後、[TAB]キーを繰り返し押すことで再生/録音/全てのどれかに選択肢を合わせ、上下キーで音量を調節します。調節が終わったら[ESC]キーでalsamixerを終了します。
4. サーバー側の準備
Googleの提供する方法で音声認識を実現する場合、下記の3つの方法が知られています。- Google Speech API v.2を用いる方法…古くからある方法。開発用途および個人用途のみ。1日50認識限定。
- Google Cloud Speech APIを用いる方法…2017年4月にリリース。利用時の登録にクレジットカードが必要。
- Google Assistant APIを用いる方法…Google Homeなどのようにコンピュータと対話するためのライブラリ。開発用途でのみ無料利用可能。一日500リクエストまで。
ここからは、Raspberry Piが通信する相手となるサーバーの準備を行います。非常に長い手順となりますので、一つずつ確実に実行していきましょう。
なお、以下の手順は「Introduction to the Google Assistant Library」の解説に基づいています。
まず、Raspberry PiのChromiumブラウザを起動してGoogleにアクセスし、お持ちのGoogleアカウントでログインしておきましょう。下図の「ログイン」ボタンから行えます。

すると、下図のようなログイン画面が現れますので、IDとパスワードを入力してログインします。

ログインが済んだら、Google Assistant APIを用いるためのプロジェクトを作成していきましょう。まず、Chromiumブラウザで「Welcome to Actions on Google」のリンクをクリックして移動してください。
リンク先に下図のようなボタンがありますので、クリックしてプロジェクトを作成します。

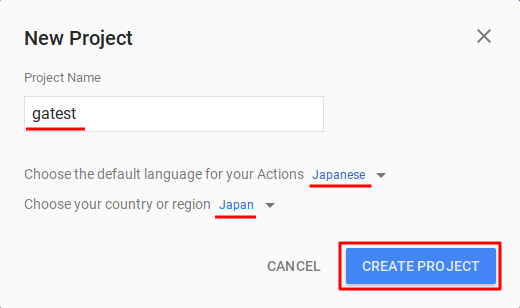
ここでは、プロジェクトの名前を「Google Assistantのテスト」の意味で「gatest」とし、デフォルト言語を「Japanese」に、国を「Japan」にしましょう。特に、言語をJapaneseにしないと、Google Assitant APIは日本語を認識してくれません。
記入と設定が終わったら「CREATE PROJECT」をクリックします。
プロジェクト作成が終わったら、Chromium上のタブは閉じずにそのまま残しておきます。
そして、そのまま今度は「Google Assistant API」のリンクをクリックしてください。
このとき、下図の赤い四角に記されているように、作成したプロジェクト「gatest」が選択されていることを確認してください。
選択されていない場合、まずその部分をクリックしてプロジェクト「gatest」を見つけて選択します(現れるまでに時間がかかることがあります)。その後、そのタブを一旦閉じ、もう一度上「Google Assistant API」のリンクをクリックすると、下図の状態が実現すると思います。
そして、そのまま「有効にする」ボタンをクリックします。

次に、「OAuth consent screen」のリンクをクリックします。すると下記のようなページが開きますので、「メールアドレスを選択してください」の部分をクリックします。選択肢として、お使いのGoogleのメールアドレスが現れますので、それを選択します。
そして、ページ下部にある「保存」ボタンをクリックします。

ここまでの作業が終わったら、今度は「デバイスモデルの登録」の作業に移ります。
さきほど閉じずに残しておいたタブに戻り、一番下にある下記のボタンをクリックします。

すると、次のような画面に遷移しますので、「REGISTER MODEL」をクリックします。

現れたウインドウに、例えば下記のように記入します。上の2つは
- Assistant SDK light
- Assistant SDK developer
これらは、本来は何を入力しても良いのですが、チュートリアルページのサンプルに合わせてこのような内容にしています。
なお、ここで表示されている「Device Model id」の内容は、以下で多用しますので、コピーしてテキストエディタなどに記して控えておきましょう。

記入やメモが終わったら「REGISTER MODEL」ボタンをクリックします。
すると、遷移した先のページで以下のようなボタンが現れますので、クリックしましょう。

すると、「client_secret_XXXXXXXXXXXX-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx.apps.googleusercontent.com.json」という形式の、非常に長い名前のファイルがダウンロードされます。保存先はデフォルトで /home/pi/Downloads となります。
このファイルを、Downloadsディレクトリからホームディレクトリ (/home/pi) に移動しておきましょう。
ターミナルを起動し、下記のコマンドを実行してください。なお、先頭の「$」はコマンドの先頭を表す記号ですので、コマンドには含めないでください。また、最後の「.」(ピリオド)にも意味はありますので、忘れずにコマンドに含めてください。
$ mv Downloads/*.json .拡張子 json のファイルを、Downloadsディレクトリからカレントディレクトリ (.) に移動しています。以下、コマンドはブラウザ上でコピーし、ターミナルへ貼り付けて実行することを推奨します。
ここまで終わったらブラウザで「NEXT」ボタンをクリックします。
次に、traitsを保存(SAVE TRAITS)するためのページに遷移しますが、ここでは「SKIP」をクリックしてスキップします。
最終的に、下記のようにModel IDが確定します。先ほどメモしたModel IDが再掲されていますね。

Model IDとともに、Project IDも以下で必要となりますので、ここで調べてメモしておきましょう。Chromiumブラウザでリソース管理ページに移動すると、先ほど作成したgatestに対する Project ID(プロジェクトID)が表示されていますのでこれもメモしておきましょう。
恐らく、Model IDとProject IDは先頭が 「gatest-xxxxx」の形式で共通となっていることでしょう。
次に、Chromiumブラウザで「アクティビティ管理」のページに移動し、下記の4点の設定を確認してください。
- 「ウェブとアプリのアクティビティ」を有効(青色)に
- 「Chrome の閲覧履歴と Google サービスを使用するウェブサイトやアプリでのアクティビティを含める」にチェック
- 「端末情報」を有効(青色)に
- 「音声アクティビティ」を有効(青色)に
5. 様々なソフトウェアのインストール
まず、ターミナルを起動し、下記の5つのコマンドを順に実行してください。なお、先頭の「$」はコマンドの先頭を表す記号ですので、コマンドには含めないでください。 長いコマンドが続きますので、ブラウザ上でコマンドをCtrl-cでコピーし、ターミナル上の「編集」→「貼り付け」によりコマンドを貼り付けて実行することを推奨します。$ sudo apt update $ sudo apt install python3-dev python3-venv $ python3 -m venv env $ env/bin/python -m pip install --upgrade pip setuptools $ source env/bin/activate3つめのコマンドでは、/home/pi/env にpython3の仮想実行環境を用意しています。Google Assistant SDKのチュートリアルでは、仮想環境でのインストールと実行を行っていますので、本ページでもそれに従います。
また、最後のコマンド「source env/bin/activate」では作成した仮想環境を優先して利用するよう設定しています。それにより、コマンドプロンプトは下記のように変化します。
(env) pi@raspberrypi:~ $本ページではこれを以下のように略記し、これの後に記されたコマンドは仮想環境で実行すべきコマンドであるものとします。
(env) $さて、Pythonの仮想環境において下記の4つのコマンドを引き続き実行していきます。これまで通りコマンドのコピーと貼り付けにより実行しましょう。実行すべきコマンドは「$」の後ろの部分のみですので注意してください。
(env) $ sudo apt install portaudio19-dev libffi-dev libssl-dev (env) $ python -m pip install --upgrade google-assistant-library==1.0.0 (env) $ python -m pip install --upgrade google-assistant-sdk[samples] (env) $ python -m pip install --upgrade google-auth-oauthlib[tool]以上でツールのインストールは完了です。次は引き続きツールとサーバーの連携作業となります。途中で作業をやめず、一気に最後まで進めた方が良いです。
6. サーバーとの連携の設定
引き続き、下記のコマンドをターミナルで実行するのですが、これはこのまま実行してもうまくいきません。(env) $ google-oauthlib-tool --scope https://www.googleapis.com/auth/assistant-sdk-prototype --scope https://www.googleapis.com/auth/gcm --save --headless --client-secrets /path/to/client_secret_client-id.json最後の「/path/to/client_secret_client-id.json」の部分を、皆さんが「サーバー側の準備」でダウンロードしたファイル「client_secret_XXXXXXXXXXXX-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx.apps.googleusercontent.com.json」で読み替えて実行しないといけないのです。
それを、下記の手順で実現しましょう。まず、上のコマンドをから末尾の「/path/to/client_secret_client-id.json」を省いた下記のコマンドをコピーし、ターミナルに貼り付けましょう。
(env) $ google-oauthlib-tool --scope https://www.googleapis.com/auth/assistant-sdk-prototype --scope https://www.googleapis.com/auth/gcm --save --headless --client-secretsそして、そのコマンドの末尾にスペースを入力し、さらに「client」まで書きます。すなわち、下記のようになります。
(env) $ google-oauthlib-tool --scope https://www.googleapis.com/auth/assistant-sdk-prototype --scope https://www.googleapis.com/auth/gcm --save --headless --client-secrets clientそこで、キーボードの[TAB]キーを押します。すると、ファイル名が補完され、下記のようにコマンドが完成します。そこでEnterを押して実行します。
(env) $ google-oauthlib-tool --scope https://www.googleapis.com/auth/assistant-sdk-prototype --scope https://www.googleapis.com/auth/gcm --save --headless --client-secrets client_secret_XXXXXXXXXXXX-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx.apps.googleusercontent.com.jsonなお、ファイル名の「XXXXXXXXXXXX-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx」の部分は人により異なりますので、「XXXXXXXXXXXX-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx」をそのままコピーしても正しい実行結果は得られませんので注意してください。 また、[TAB]キーを押したときにファイル名が補完されるのは、「サーバー側の準備」で、
- ファイルをDownloadsディレクトリに保存したこと
- 保存したファイルをDownloadsディレクトリからホームディレクトリに移動したこと
基本的に本ページの内容は一つでも正しく実行されていない項目があればうまくいかないとお考え下さい。
さて、コマンドが正しく実行されると、下図のように、ブラウザでアクセスすべきアドレスが現れます(図を拡大表示して形式を良く観察してください)。

このアドレスの部分(「https://」から「consent」まで)をマウスでなぞり、ターミナル上で「編集」→「コピー」を選択してコピーします(Ctrl-cでコピーしようとするとコマンドが終了してしまいますので注意しましょう)。
そして、chromiumブラウザのアドレス欄にコピーされたアドレスを貼り付けてEnterし、ブラウザでページを移動します。
すると、アカウントの選択が求められた後、さらに下図のようにブラウザ上にgatestからのリクエストが表示されますので、許可ボタンをクリックしてください。

すると、ブラウザで下記のように長いコードが表示されますので、マウスでなぞってCtrl-cでコピーしてください。

そして、先ほどのターミナルに戻り、「編集」→「貼り付け」で貼り付け、Enterキーを押します。
すると、下図のように「credentials saved: /home/pi/.config/google-oauthlib-tool/credentials.json」と表示されて処理が完了します。

7. 動作確認
以上で動作確認を行う準備が整いました。 まず、動作確認および音声認識用のファイルをダウンロードします。ダウンロードは通常環境と仮想環境のどちらで行っても構いません。$ wget https://raw.githubusercontent.com/neuralassembly/raspi/master/controlTV-ga.py次に、動作確認を行います。もしこの時点でPythonの仮想環境に入っていなければ、次のコマンドで仮想環境に入ります。
$ source env/bin/activateそして、実行すべきコマンドは下記になります。斜体部は上で確認した皆さんのProject IDとModel IDで置き換えて実行してください。
$(env) $ python controlTV-ga.py --project_id project-id --device_model_id model-id実行したら、マイクに向かって「オーケー グーグル」と話しかけてください。

認識されれば上図のように「ON_CONVERSATION_TURN_STARTED」と表示されますので、そのまま「今何時?」などと話しかけてみてください。スピーカーから返答が出力されるはずです。
なお、AndroidスマートフォンやiPhoneなどをお持ちの場合、Googleのアプリケーションで「設定」→「設定」→「Assistant SDK light」とたどり、以下のように「アカウントに基づく情報」をオンにすると、「私は誰?」や「今日の予定」など、アカウントの個人情報に基づく質問にも答えてくれるようになります。なお、Googleのアプリケーションは、Android用とiPhone/iPad用があります。


最後に、このサンプルプログラムを終了するには、キーボードでCtrlキーを押しながらcキーを押してください(Ctrl-cといいます)。
8. 音声でのテレビの操作
この状態で、冒頭の動画のように「オーケーグーグル、テレビつけて」などとマイクに話かけると、 テレビをオンにする信号赤外線LEDより出力される、という流れです。ダウンロードしたプログラム controlTV-ga.py のうち、テレビの操作に関わる部分を一部抜きだしたのが以下の部分になります。
if event.type == EventType.ON_RECOGNIZING_SPEECH_FINISHED:
s = event.args['text']
print(s)
if 'テレビ' in s and ('つけて' in s or 'オン' in s):
args = ['irsend', '-#', '1', 'SEND_ONCE', 'TV', 'power']
try:
subprocess.Popen(args)
except OSError:
print('command not found.')
assistant.stop_conversation()
elif 'テレビ' in s and ('消して' in s or 'オフ' in s):
args = ['irsend', '-#', '1', 'SEND_ONCE', 'TV', 'power']
try:
subprocess.Popen(args)
except OSError:
print('command not found.')
assistant.stop_conversation()
elif 'NHK 教育' in s or 'Eテレ' in s:
args = ['irsend', '-#', '1', 'SEND_ONCE', 'TV', 'ch2']
try:
subprocess.Popen(args)
except OSError:
print('command not found.')
assistant.stop_conversation()
少し解説しましょう。
この部分は、「オーケーグーグル」と話しかけた後に発した言葉が「Google Assistant API」により音声認識された後の処理を表しています。「s」という変数に音声認識結果が格納されています。
そこで、「if 'テレビ' in s」と書くと、「文字列 s に'テレビ'という語句が含まれていたら」という条件となります。
さらに、and (なおかつ)、or (または)を組み合わせて条件を作成しています。
結果的に「'テレビ' in s and ('つけて' in s or 'オン' in s)」という条件で、
「sに’テレビ'と'つけて'が含まれている場合」または「sに’テレビ'と'オン'が含まれている場合」にテレビの電源がつくという動作になります。
条件文を作る際のカッコ「()」の使い方にも注意しましょう。
なお、テレビの電源を入れるための信号は、「irsend -# 1 SEND_ONCE TV power」という命令を実行することで行っています。この命令を有効にする方法は本書5章で解説されていますので、参照してください。赤外線LEDを用いた回路の作成方法も解説しています。
それらの準備を済ませると、冒頭の動画のように音声に応じてテレビを操作することができます。
なお、音声認識の結果に基づいてテレビを操作した後、「assistant.stop_conversation()」という命令を実行してGoogle Assistantとの会話をそこで打ち切っています。そうしないと、テレビへの命令を受け付けるたびにGoogle Assistantが「申し訳ありません、お役に立てそうにありません」と音声を発してしまうためです。
9. Google Assistantでのテレビ操作についての注意
以上のように、Google Assistantによる音声認識結果を直接if文で判定させることでテレビの制御を行いました。実は、Google Assistantには、家電などのオンオフを制御する公式な方法があります。例えば、こちらのページではRaspberry Piに接続したLEDをオンオフする方法が解説されています。
しかし、この方法を用いてテレビのチャンネルを変える方法が思いつかなかったので、本ページでは音声認識結果を直接if文で判定する方法を取りました。
10. 仮想環境上のPythonを利用する際の注意
なお、本ページではGoogle Assistant SDKの公式ページで行われているのに合わせ、Python3の仮想環境を作成してその上でプログラムを実行しました。この方法を用いると、デフォルトでは電子工作用のライブラリを用いることができません。本書ではGPIOにアクセスするためにRPi.GPIOというライブラリを用いましたが、そのままではそれを利用することができないのです。
既存ライブラリをPythonの仮想環境でも利用可能にするには、設定が必要です。
設定ファイル /home/pi/env/pyvenv.cfg 内にある
include-system-site-packages = falseという行を
include-system-site-packages = trueに変更して保存すると、既存ライブラリが仮想環境でも利用可能になります。
11. Google Assistant APIの利用制限について
Google Assistant APIは無制限に使えるわけではなく、- 1日当たり500リクエスト
- 100秒当たり100リクエスト
どの程度Google Assistant APIを利用しているかを確認する方法を以下に記します。
「リソースの管理」ページに行き、プロジェクト名をクリックします。 現れるページの左のカラムで「割り当て」をクリックします。 そして、現れた右の表示エリアで「Google Assistant API」を見つけてクリックすると、利用状況のグラフを見ることができます。
「太平洋時間(PT)の午前 0 時にリセット」と書かれておりますので、 その時間が過ぎればリクエスト数がリセットされてまた利用可能になるはずです。
13. Raspberry Pi起動時にプログラムを自動起動する
ここで紹介したcontrolTV-ga.pyは、実行するためのコマンドがやや複雑でした。このコマンドをシンプルに実行できるようにし、さらにRaspberry Pi起動時に自動で実行する方法を解説します。
まず、コマンドをシンプルにする方法です。ターミナルを起動し、以下の2つのコマンドを順に実行しましょう。
$ wget https://raw.githubusercontent.com/neuralassembly/raspi/master/start-assistant.sh $ chmod 755 start-assistant.sh以後実行するのはstart-assistant.shというコマンドになるのですが、その前にこのファイルの中身を編集する必要があります。まず、下記のコマンドを実行することでテキストエディタleafpadでstart-assistant.shを編集用に開きます。
$ leafpad start-assistant.shこのファイルの中身は下記のようになっています。
#!/bin/bash source /home/pi/env/bin/activate # set if you are inside firewall #export http_proxy=http://(proxy server):(port)/ #export https_proxy=http://(proxy server):(port)/ #export ftp_proxy=http://(proxy server):(port)/ python /home/pi/controlTV-ga.py --project_id gatest-xxxxx --device_model_id gatest-xxxxx-assistant-sdk-light-xxxxxxこの最後の行の「gatest-xxxxx」と「gatest-xxxxx-assistant-sdk-light-xxxxxx」の部分を皆さんが使っているモデルのIDに変更してください。この行が、いつも実行しているcontrolTV-ga.pyを実行しているコマンドが記されていることはわかるでしょう。
さらに、controlTV-ga.pyの位置がユーザpiのホームディレクトリ (/home/pi) であることを前提とされていることにも注意してください。
変更が終わったら、ファイルを上書き保存してleafpadを閉じましょう。
その後ターミナルを起動して、下記のコマンドを実行しましょう。これは仮想環境に入らずに実行して構いません。このファイル内部で仮想環境の利用設定とcontrolTV-ga.pyの実行が両方行われるので、プログラムの実行が容易になるというわけです。
$ ./start-assistant.shここまでが実現できたら、Raspberry Pi起動時の自動実行が下記のように実現されます。
まず、下記のコマンドを実行してください。必要なファイルをダウンロードし、適切な場所に配置しています。
$ wget https://raw.githubusercontent.com/neuralassembly/raspi/master/assistant.service $ sudo mv assistant.service /etc/systemd/systemその後、下記のコマンドを実行すると、再起動時にcontrolTV-ga.pyが自動で起動します(ターミナルの表示がないのでわかりにくいですが…)。
$ sudo systemctl enable assistant上記の動画では、Raspberry Pi本体にキーボードとマウスが取り付けられていませんが、これはこの自動起動が行われていたからです。
自動起動を無効にするには下記のコマンドを実行します。
$ sudo systemctl disable assistant
おかげさまで、なんとか、Google Assistantでテレビを操ることができました。ありがとうございます。
返信削除ところで、さらに機能を追加して、音声で曲目を話すと/home/piに保管されているmp3の音源を再生しようとチャレンジしているのですが、反応してくれません。どうしたらよいのでしょうか。アドバイスいただけると幸いです。
以下のスクリプトをcontrolTV-ga.pyに追加してみたのですが...
elif '卒業写真' in s:
args = ['mpg321', 'sotugyou.mp3']
try:
subprocess.Popen(args)
except OSError:
print('command not found.')
assistant.stop_conversation()
まず、前提条件として下記をご確認頂きたいと思います。
削除(1) controlTV-ga.pyとsotugyou.mp3 とが同じディレクトリに存在する
(2) コマンドプロンプトで「mpg321 sotugyou.mp3」を実行したときに音楽が再生される
(3) 音楽再生機能を組み込む前のcontrolTV-ga.pyの音声認識機能は正常に動作する
なお、(3)の実行方法には、
(3-1) Python仮想環境で
(env) $ python controlTV-ga.py --project_id gatest --device_model_id my-model
を実行する(my-modelは人によって異なる)
(3-2) 仮想環境に入らず、
./start-assistant.sh
を実行する(ただし、start-assistant.shを事前に適切に編集しておく必要あり)
(3-1)の方が、controlTV-ga.pyからmpg321が実行される際に表示されるメッセージが多いので、
機能が完成するまでは(3-1)の方法で実行した方が良いと思います。
さて、上記が確認されたら、注意すべきはcontrolTV-ga.pyの編集方法のみだと思われます。
私の場合、下記のように
「assistant.stop_conversation()」と「else:」の間に
下記のように7行追加することで、音楽再生できました。
ただし、このコメント欄でうまく表示されるかわかりませんが、
字下げを示す空白文字数が各行で正しい数になっていることを
よくチェックしてください。
#####
assistant.stop_conversation()
elif '卒業写真' in s:
args = ['mpg321', 'sotugyou.mp3']
try:
subprocess.Popen(args)
except OSError:
print('command not found.')
assistant.stop_conversation()
else:
#####
なお、このスクリプトを最終的に自動実行しようという場合、
args = ['mpg321', 'sotugyou.mp3']
の行は
args = ['mpg321', '/home/pi/sotugyou.mp3']
の方が良いかもしれません。
(もちろん、(3-1)の方法で成功することが先決ですが)
以上でいかがでしょうか。
教えていただきまして、大変ありがとうございました。
返信削除ご指導の様に、mp3再生スクリプトを「ボリューム下げて」の下(最後)に移して、
ファイル名を明示的に'/home/pi/sotugyou.mp3'にしたら無事
「ok googol 卒業写真」で再生できました。感謝感激です。
少し気になるのは、
(env) $ python controlTV-ga.py --project_id gatest --device_model_id my-modelのところで
[3948:3970:ERROR:audio_input_processor.cc(748)] Input error
ON_MUTED_CHANGED:
{'is_muted': False}
ON_START_FINISHED
[3948:3978:ERROR:audio_input_processor.cc(748)] Input error
のようなエラーメッセージが出ることですが...
これは、以前から出ていた問題ですが、実用上は、差支えありません。
次の課題は、/home/piにたくさんの曲ファイルを移して、
controlTV-ga.pyに「卒業写真」同様大量に追記してみようと思います。
いうなれば、音声認識ジュークボックスにしてしまうことです。
ただ、結構手間がかかることと、ファイルが大きくなると、サーチに時間がかかり、レスポンスがどうなるか、気になりますね。
もっと合理的な方法、
例えば「卒業写真.mp3」のような日本語曲名のファイルを/home/piに
大量保管して、python controlTV-ga.pyのプログラムを改造して
発話した曲名をキーにファイル名をサーチして、
マッチングしたら、mpg321 に'曲名'.mp3をつけて
実行できるようになれば、とても便利になりますね。
いずれにせよ。大変ありがとうございました。
次は、機械学習の本も購入して、実験してみますね。
ありがとうございます。
削除ところで、
ERROR:audio_input_processor.cc
というエラーは私はこれまで見たことがありません。
上記エラーをGoogleで検索すると、
下記のような原因の候補が見つかりますね。
・Raspbianのバージョンが古い可能性がある
・asoundrcの設定に問題がある可能性がある
・別アプリケーションでマイクが使われている可能性がある
ただし上記の場合は、マイクによる音声認識自体に
失敗していることが多いように見えます。
今回のように問題なく機能しているのならば
気にしなくても良いのかもしれませんね。
>Raspbianのバージョンが古い可能性がある
削除当方のOSのバージョンは
pi@raspberrypi:~ $ cat /etc/debian_version
9.1のようです。
最近インストールしたので、そんなに古くは
ないのではと推察されますが...
>asoundrcの設定
当方の.asoundrcの内容は
pcm.!default {
type asym
capture.pcm "mic"
playback.pcm "speaker"
}
pcm.mic {
type plug
slave {
pcm "hw:1,0"
}
}
pcm.speaker {
type plug
slave {
pcm "hw:0,0"
}
}
です。
マイクはUSB接続、スピーカーは、3.5プラグ出力です。
いずれにせよ、使用に支障ないので、無視しておきますね。
mp3ファイルは51曲ホームディレクトリに保管して
controlTV-ga.pyの追記は終わりました。
これを自動車に乗せると、ハンズフリーのカーステレオに
なるかもしれませんね。
曲名発話のgoogle assistantからのリターンが当方からの
意図通りに解釈してれるか、少し気がかりになりました。
秦基博の楽曲名「アイ」は、「愛」か「あい」か「アイ」
どれで記述したら良いかという問題です。
elif 'アイ' in s or 'あい' in s or '愛' in s:
とすることにより、どう解釈してもひっかかるのかもしれませんが、平井堅の「even if」のような英語のタイトルの場合は
どう解釈するのか、気になりますね。
とりあえず「イーブンイフ」にしてみました。
google assistantの言語設定は「日本語」にしましたが
たまに気まぐれで、英語で答えてくるときがあり、少し笑えます。色々ありがとうございました。
だめですね。
削除51曲分をcontrolTV-ga.pyに挿入しましたがうまく動かなくなりました。
「テレビつける」「チャンネル変える」「テレビ消す」は実行しますが、音楽再生が一切できません。また、google assistansからの返答(「今何時」等)も一切できなくなってしまいました。
字下げ等のエラーは取り除いて、チェックはしたつもりなのですが...
内容が書籍および補足ページの範囲から逸脱してきましたので、
削除この問題につきましてはそろそろ完結とさせていただきたいと思います。
また、ご質問に関しましては
本ページのコメント欄でお願いしたいと思います。
ご理解ください。
問題の原因はわかりませんが、
一つ目の原因として思いつくのは、
SDカードの容量が足りなくなっていないかということです。
「dfコマンド」でGoogle検索すると、
SDカードの空き容量を調べる方法がわかります。
二つ目の可能性としてはGoogle Assistant APIの一日の利用制限に
引っ掛かっていることが考えられます。
下記の方法で確認することができます。
「リソースの管理」ページに行き、
https://console.cloud.google.com/cloud-resource-manager
プロジェクト名をクリックします。
現れるページの左のカラムで「割り当て」をクリックします。
そして、現れた右の表示エリアで「Google Assistant API」を見つけてクリックします。
これを見ると
「1日当たり500リクエスト」
「100秒当たり100リクエスト」
という2つの制限があり、
これらに引っかかった可能性があります。
その場合、「太平洋時間(PT)の午前 0 時にリセット」と書かれておりますので、
時間がたてば復活するとおもわれます。
色々とご迷惑をおかけしましたが、
削除なぜか、無事動きました。
但し、いくつか問題があります。
明日の予定を尋ねると、
これまでは、googleアカウントにリンクしていたgoogleカレンダーの予定が応答されていたのですが、平原綾香の「明日」に反応して、曲を再生してしまいます。
また、発話が日本語変換された際の漢字・ひらがな・かたかなの属性が意図したものと違って、どうしてもヒットしない曲もあります。曲のプレーが止まらずに最後まで聞くしかないこと。次々にリクエストすると、何重奏にもなって演奏されてしまう等、愚直なジュークボックスですが、そのあたりが、かわいらしくて、かえって愛着が湧きますね。
AIを操るのは、一筋縄ではないことがわかって、いい勉強になりました。本来の趣旨から脱線しまくったことをお許しください。
本当にありがとうございました。
はじめまして、私はgoogle-assistantが反応したとき、ledを光らせたり、ボタンで起動したりする。プログラムを教えてくださればお願いします。
返信削除